

این مقاله در ماهنامه رایانه، شماره 244، اسفندماه 1392، صفحات 21 تا 38 به چاپ رسیده است.
مقدمه
از ساليان دور کاربران رایانههای شخصی در آرزوی استفاده از دو يا چند پردازنده بر روی يک بُرد اصلی بودهاند. در آن زمان برای تحقق اين آرزو، کاربران مجبور به استفاده از بُرد اصلی با دو سوکت نصب پردازنده بودند که هزينه مالی سنگينی را به کاربر تحميل مینمود.
امروزه شاهد هستيم که مدلهای متعدد پردازندههای چندهستهای Intel و AMD به وفور در بازار سخت افزار يافت میشوند. طبیعتا با وجود مدلهای مختلف پردازنده در بازار سختافزار، کاربران دغدغه بهترین انتخاب را خواهند داشت. البته آشکار است که AMD هنوز موفق نشده در زمینه کیفی و میزان فروش پردازندهها از Intel سبقت گیرد ولی نوآوریهای AMD و ویژگیهایی که در پردازندههای خود استفاده مینماید بسیار جالب و ارزشمند است. بنابراین جهت انتخاب صحیح پردازنده، آگاهی از ویژگیها، امکانات و نوآوریهای انجام شده بسیار راهگشا میباشد. البته در مقاله ارائه شده هدف این نمیباشد که پاسخی برای پرسش “پردازندههای Intel بهتر از پردازندههای AMD هستند؟” ارائه گردد. در هرمقالهای که در رابطه با پردازنده جدیدیکه توسط Intel یا AMD ارائه میشود، ویژگیهای پردازنده انتخاب شده توسط نگارنده، بررسی و بحث شده و در نهایت خوانندگان فهیم هنرگاه زایا میتوانند پاسخی برای سوال مطرح شده فوق داشته باشند.
در این مقاله به چگونگی ارائه پردازندههای چند هستهای، مراحل عرضه پردازندههای چند هستهای، معماری 64 بیتی AMD، معماری AMD Fusion، پردازنده با واحد پردازش تسریع شده (APU)، معماری سیستم نامتجانس (HAS)، مدل برنامهسازی OpenCL ،C++ AMP، معماری گرافیکی GCN خواهیم پرداخت.
سیر گذر از معماری يک هستهای به چند هستهای
در راستای حرکت به سوی برآوردهسازی نیاز استفاده از چند پردازنده در يک رایانه شخصی، شرکت Intel برای اولين بار تکنولوژی Hyper-Threading را در طراحی نسل چهارم پردازنده Pentium 4 استفاده نمود. این تكنولوژي يك پردازنده فيزيكي تک هستهای را قادر ميسازد كه دو كد مستقل را كه Thread ناميده ميشوند، به صورت همزمان اجراء نمايد. يك پردازنده كه از تكنولوژي HT استفاده مینمايد، شامل دو پردازنده منطقي است كه هر كدام از اين پردازندههای منطقي داراي حالت كاری مخصوص به خود میباشند. اين حالت كاري Architectural State (AS) ناميده ميشود. منظور از AS اين است كه هر پردازنده منطقي شـامل ثَباتهاي قطعه، ثَباتهـاي كنترلي، ثَباتهـای رديـابی و ثَباتهـای همه منظوره مخصوص به خود میباشد. هر پردازنده منطقي در حالت AS داراي كنترل كننده پيشرفته قابل برنامهريزی وقفه Advanced programmable interrupt Controller (APIC) مخصوص به خود است.
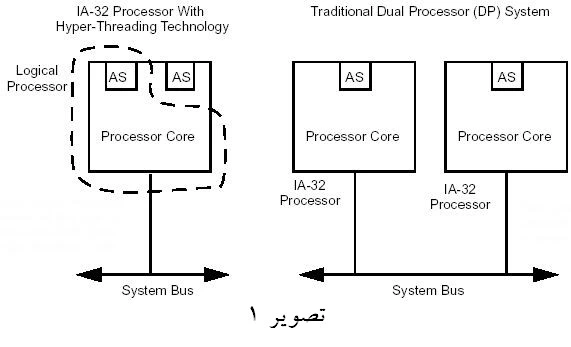
در تصوير 1 تفاوتهای یک سيستم دو پردازنده ای (Dual Processor) و سيستم تک پردازندهای مبتنی بر تکنولوژی HT را مشاهده مینمائيد. هر دو پردازنده منطقی بر روي يك تراشه وجود دارند و سيستم دارای يك پردازنده فيزيكي تک هستهای میباشد. برخلاف پيكر بندي Dual Processor كه مبتني بر دو پردازنده مستقل فيزيكي است، پردازنده منطقي در يك پردازنده فيزيكي تکهستهای مبتني بر تكنولوژي HT، منابع اجرايي هسته پردازنده را به صورت اشتراكي استفاده نمیكند. اين منابع شامل موتور اجرايي، حافظههاي نهای، واسط گذرگاه سيستم و نرمافزارهاي قرار داده شده در حافظه ROM میباشند. شرکت Intel امروزه در پردازندههای خود (Core i) همچنان از معماری HT استفاده مینماید.
شرکت AMD در رقابت با شرکت Intel، معماری AMD64 را ارائه نمود. پردازندههای مبتنی بر معماری AMD64 اولین نسل پردازندههای 64 بيتي شركت AMD میباشند. در طراحی پردازندههای رايج آن زمان، کنترل کننده حافظه جزئی از پل شمالی بُرد اصلی بود. هنگام وجود يك درخواست Read، كنترلكننده حافظه، درخواست خواندن را به گذرگاه حافظه و سپس به حافظه ارسال مینمود و پس از انجام يكسري عمليات، داده مورد نظر جستجو و پيدا شده و به كنترل كننده حافظه ارسال میگردید. كنترل كننده حافظه، داده را دريافت و با مشاركت پل شمالی به واسط گذرگاه تحويل میداد و در نهايت داده به پردازنده ارسال میشد. بنابراين بين پل شمالي و پردازنده يك تاخير زماني وجود داشت. در آن زمان دو راهکار برای از بين بردن اين تاخير پيشنهاد گردید. راهکار اول استفاده از حافظه نهان L3 بين پل شمالی و پردازنده، جهت كاهش تاخير زمانی و افزايش پهنای باند بود. در آن زمان شرکت Intel در طراحی پردازنده Pentium 4 Extreme Edition اين راه حل را برگزيد. اما شركت AMD راهکار دوم يعنی قراردادن كنترل كننده حافظه در داخل پردازنده را برگزيد. معماري AMD64 از كنترل كننده DDR2 DRAM به صورت دوكاناله با رابط 128 بيتي جهت استفاده مینمود.
شرکت Intel در قدم بعدی پردازنده Pentium 4 را از رده خارج و پردازنده دو هستهای Pentium D را جايگزين نمود. در طراحی پردازنده Pentium D، هر هسته پردازنده بر روی يک تراشه قرار گرفته و دو تراشه بر روی يک Package نصب شدند.

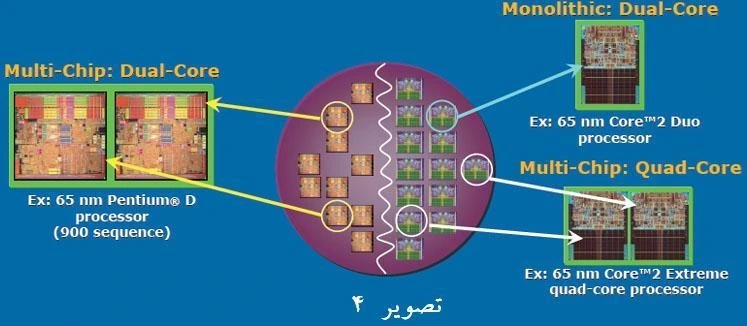
در تصوير 2 مشاهده میشود که بر روی يک Package دو تراشه مستقل نصب شده و در عمل پردازنده دارای دو هسته میباشد. شرکت Intel تاکنون از 3 روش برای ساخت پردازندههای چندهستهای استفاده نموده است. روش اول چند تراشهای (Multi-chip) ناميده میشود. در روش چند تراشهای، هر هسته پردازنده بر روی يک تراشه مجزا قرار گرفته و دو تراشه بر روی يک Package قرار میگيرند. در روش چند تراشهای، ارتباط بين دو هسته از طريق FSB صورت میپذيرد. بنابراين اگر يک هسته پردازنده به اطلاعات حافظه نهان هسته ديگر نياز داشته باشد، دسترسی از طريق FSB صورت میپذيرد. در مرحله بعدی شرکت Intel اقدام به جايگزينی معماری Intel Core بجای NetBurst نمود و طراحی پردازندههای دو هستهای خود را با روش دوم انجام داد. روش دوم روش يکپارچه (monolithic) میباشد. در اين روش هر دو هسته بر روی يک تراشه قرار گرفته و تراشه نيز بر روی يک Package نصب میگردد.

شرکت Intel تمام پردازندههای خانواده Core 2 را با روش يکپارچه توليد نموده است (تصوير 3). در اين حالت دو یا چهار هسته فیزیکی پردازنده برای ارتباط با يکديگر، نيازی به FSB ندارند. بنابراين، هر يک از هستهها برای دسترسی به اطلاعات حافظه نهان هسته ديگر، از FSB استفاده نمیکنند چرا که هستهها دارای يک حافظه نهان مشترک نصب شده بر روی يک تراشه میباشند. بنابراین با حذف گذرگاه FSB، کارآيی پردازنده افزايش مییابد. شرکت Intel پردازندههای چهار هستهای Core i را با روش سوم ارائه نمود. روش سوم در اصل ترکيبی از دو روش يکپارچه (monolithic) و روش چند تراشهای (Multi-chip) بود. در روش چند تراشهای يکپارچه، دو تراشه يکپارچه بر روی يک Package قرار میگيرند. اگر هسته 1 يا 2 نياز به ارتباط با هسته 3 يا 4 داشته باشند يا بخواهند به اطلاعات حافظه نهان هسته ديگر دسترسی داشته باشد، FSB اين کار را انجام خواهد داد.
در نهایت با دسترسی شرکت Intel به فناوری تولید 32 نانومتری، پردازندههای خانواده Core i با روش یکپارچه تولید و به بازار عرضه شدند.
معماري AMD64
در معماری AMD64 هسته پردازنده داراي 9 واحد پردازش كننده عمليات صحيح و اعشاري مي باشد كه در ميان آنها يك واحد سازگار با دستورات SSE2 قرار دارد (تصوير5).
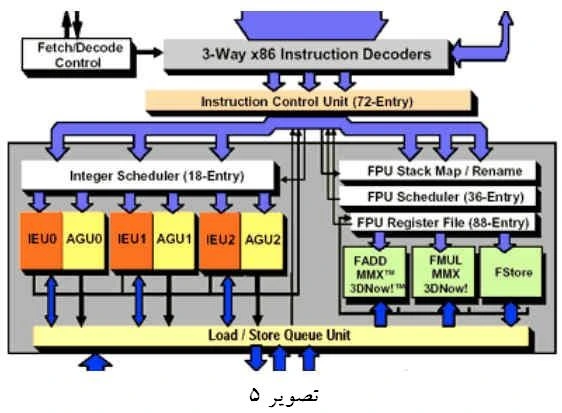
اين واحدهای پردازش كننده از طريق سه خط لوله با قسمت كدگشا در ارتباط هستند. سه واحد كدگشا امكان بافر نمودن هشت مدخل را براي شش واحد پردازش عدد صحيح دارا میباشند. واحدهای پردازش صحيح شامل سه ALU و سه واحد واحد توليد آدرس (Address Genreation Unit) میباشند. واحدهای سه گانه تولید آدرس وظيفه خواندن (يا نوشتن) دادهها از (يا در) حافظه نهان را برعهده دارند. با توجه به افزايش واحدهای پردازشگر در این معماری، حجم كار پردازش هر واحد زياد افزايش نيافته است. چراكه در صورت افزايش حجم كار هر واحد، واحدهای تغذيه كننده جهت رساندن دادههاي لازم دچار مشكل خواهند شد. در قسمت حافظه نهان، ظرفيت به يك مگابايت افزايش يافته است. در قسمت اجرای دستورالعمل، تغيرات زيادی بر روی بافر TLB انجام شده و مدخلهای آن افزايش يافته است. TLB حافظه واسطه كوچكي است كه دادههای مربوط به فرآیند تبديل آدرسهای منطقي به آدرسهای فيزيكی را نگهداری میكند. علت افزايش مدخلها اين است كه هرچه مداخل بيشتری وجود داشته باشد، هنگام محاسبه آدرس فيزيكی، حجم بارگذاری از جدول ترجمه به TLB كمتر خواهد بود كه منجر به صرفه جويی در زمان شده و برخی دستورات معين با سرعت بيشتری اجرا خواهند شد. جهت بهتر شدن مديريت TLBها هنگام جابجايی ميان Taskها، يك Flush Filter با 32 مدخل تعبيه شده است. با استفاده از Flush Filter امكان به اشتراك گذاشتن يك TLB بين چند Thread وجود دارد. در معماري AMD64 با افزايش ظرفيت Global History Counter به بيشتر از 16 كيلوبايت، عملكرد واحد پيشبينی انشعاب بهتر شده است. نوآوری اصلی شركت AMD در این معماری يكپارچه نمودن يك كنترلكننده حافظه با پردازنده است. با توجه به يكپارچگی انجام شده، زمان وقفه در پردازندههای مبتنی بر معماری AMD64 به کمتر از 80 نانوثانيه کاهش یافت. بنابراين به دليل يكپارچه شدن كنترل كننده حافظه با پردازنده، شركت AMD به جای گذرگاه FSB از گذرگاه Hyper Transport استفاده نمود.
معماری AMD64 K10
شرکت AMD در زمان ارائه معماری K8 یعنی سال 2003 ميلادی در نظر داشت که از سال 2005 ميلادی پردازندههای سرور خود را با معماری K9 و پردازندههای روميزی را با معماری K8 عرضه نمايد. اين طرح در عمل اجرايي نگرديد تا اينکه در سال 2007 ميلادی معماری K10 عرضه گردید.
تغييراتی که در معماری K10 اعمال شده است عبارتند از:
- دستورات SSE به صورت 128 بیتی عمل مینمايند.
- واکشی دستورات به صورت 32 بايت بر سيکل(32 byte/cycle) انجام میشود. يعنی امکان واکشی 32 بایت دستور در هر سيکل وجود دارد
- پهنای باند حافظه نهان داده دو برابر شده است. در هر سيکل، امکان دريافت/ ارسال دو مجموعه 128 بیتی از حافظه نهان داده وجود دارد.
- پهنای باند حافظه نهان L2 به 128 بیت در هر سيکل افزايش يافت.
- در هر هسته پردازنده ظرفیت حافظه نهانL1 به 64 کیلوبایت و حافظه نهان L2 به 512 کیلوبایت افزایش یافت.
- پردازنده از يک حافظه نهان L3 به ظرفيت 2 مگابایت استفاده مینمود.
- کنترل کننده حافظههای نهان هر هسته، در داخل هسته قرار گرفته است.
- گذرگاه Hyper Transport به نگارش 3 ارتقاء يافت. گذرگاه HT 3.0 توانايي انتقال داده با نرخ 8GB/s با فرکانس 3.8GHz را داشت و از شکاف توسعه گرافيکی PCI Express 2.0 پشتيبانی مینمود.
- استفاده از واحد پيش واکشی پيشرفته حافظه
معماری AMD Fusion

شرکت AMD معماری جايگزين K10 را با نام Fusion معرفی نموده است. در فيزيک هسته ای Fusion به معني هم جوشي است و در ادامه مقاله توضیحات ارائه شده علت انتخاب واژه همجوشی را مشخص خواهد نمود. در آن زمان یعنی سال 2007 میلادی شرکت AMD اعلام نمود که اولين هدف معماری Fusion مجتمع نمودن پردازنده گرافيکي (GPU) در پردازنده اصلي است. توجه داشته باشید که در آن زمان شرکت Intel نسل اول پردازندههای Core i خود را عرضه نموده بود و عملا در سال 2013 میلادی پردازندههای Haswell با پردازنده گرافیکی توکار در CPU ارائه شدند!
CPU ، GPU و APU
برای درک صحیح و تفکیک مفاهیم مورد استفاده اجازه دهید مفاهیمی نظیر CPU ،GPU و APU را به صورت خلاصه مرور نمائیم.
CPU مخفف Central Processing Unit به معنای واحد پردازش مرکزی میباشد. CPU پردازندهی اصلی، پردازنده یا ریزپردازنده نیز نامیده میشود. علت انتخاب عنوان واحد پردازش در این است که در CPU تمام فعالیتهای اصلی نظیر واکشی، رمزگشایی، اجرا و بازنویسی صورت میگیرد. اگر پردازنده از یک سیستم رایانهای حذف گردد، عملکرد آن متوقف خواهد شد. نقش پردازنده اصلی در انجام عملیاتی مانند محاسبات یا بارگذاری سیستم عامل بسیار مهم است.
GPU مخفف Graphical Processing Unit به معنای واحد پردازش گرافیکی است و مسئولیت نمایش تصاویر و ویدیوها بر روی نمایشگر را بر عهده دارد. البته این امکان وجود دارد که رایانه بدون پردازندهی گرافیکی عملیاتی را انجام دهد اما برای نمایش تصویر و اتصال یک نمایشگر به رایانه وجود پردازنده گرافیکی الزامی است. در برخی موارد برای استفاده از سیستمهای رایانهای سرویس دهنده نیازی به وجود نمایشگر نمیباشد و از مکانیزم اتصال ترمینالی استفاده میشود و دستورات از آن طریق به رایانه سرویس دهنده ارسال میشوند.
تفاوت CPU و GPU در این است که پردازنده گرافیکی وظیفه پردازش مقادیر زیادی داده گرافیکی را برعهده دارد و میلیونها یا میلیاردها محاسبه را در کسری از ثانیه انجام میدهد. تعداد هستههای GPU بسته به سازندهی آن متفاوت است. nVIDIA و AMD (ATI) دو تولیدکنندهی بزرگ تراشه گرافیکی دو استراتژی متفاوت در طراحی واحد پردازش گرافیکی دارند. استراتژی nVIDIA افزایش توان عملیاتی و کاهش تعداد هسته گرافیکی است اما استراتژی AMD افزایش تعداد هستهها با توان کمتر است. یک کارت گرافیک معمولی nVIDIA دارای 68 هسته میباشد ولی کارت گرافیک معادل AMD حدود 1500 هسته دارد. واحد پردازش گرافیکی در متداولترین شکل خود یک کارت گرافیکی است. کارت گرافیکی بر روی شکاف PCI Express بُرد اصلی نصب میشود. برخی بُردهای اصلی دارای کارت گرافیکی توکار هستند. به بیان دیگر تراشه گرافیکی به صورت مجتمع و یکپارچه بر روی بُرد اصلی تعبیه شده و قطعه جداگانهای نمیباشد.
APU مخفف Accelerated Processing Unit به معنای واحد پردازش شتابیافته است و از شامل اجزاء مختلفCPU ، GPU و پُل شمالی میباشد. در APU اجزاء ذکر شده به صورت مجزا قرار نگرفتهاند بلکه یکپارچه شدهاند. شرکت AMD در سال 2008 میلادی پردازندههای خود را با نام پردازنده چند هستهای نامتجانس (Heterogeneous Multicore processor) معرفی نمود. اين پردازندهها دارای APUهای متعدد میباشند. در معماری Fusion پردازندههای شرکت AMD دارای دو يا چند هسته CPU و xPU میباشند. واحد xPU میتواند اجزايي مانند هسته محاسباتی، کنترلکننده حافظه، رابط I/O یا هسته گرافیکی باشد. هر پردازنده بر اساس نياز کاری شامل يک يا چند xPU میباشد. در تصوير 7 مشاهده میشود که يک پردازنده میتواند شامل يک هسته CPU و يک xPU مانند GPU باشد. در حالتی ديگر پردازنده دارای سه هسته CPU و يک xPU میتواند باشد. در این حالت توان پردازشی بالا مورد نظر است. در حالتی متفاوت و بر اساس نياز کاری، امکان وجود سه xPU و يک هسته CPU نيز وجود دارد. در این حالت توان پردازشی بالا مورد نظر نمیباشد.
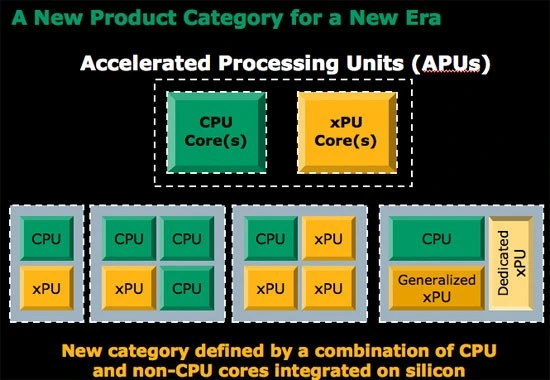
از سال 1981 تا 2010 ميلادی، پردازندههای تک يا چند هستهای به صورت متجانس يا Homogenous عرضه میشدند. پردازندههای نامتجانس يا Hetergenous شرکت AMD در سال 2010 ميلادی عرضه تجاری شده و از آن زمان پردازندههای A Series در سبد محصولات شرکت AMD قرار گرفته است. در اوایل سال 2012 میلادی شرکت AMD معماری Heterogeneous Systems Architecture (HSA) را معرفی نمود.
بررسی معماری HSA
Heterogeneous System Architecture به معنی معماری نامتجانس سیستم است. تا قبل از این معماری، تنها CPU مسئولیت اجرای پردازشهای عمومی را برعهده داشت و پردازشهای گرافیکی وظیفه GPU بود. پردازنده گرافیکی برای انجام محاسبات خاص مثل محاسبات گرافیکی به صورت موازی کاربرد دارد. امروزه توانمندی پردازندههای گرافیکی در حدی است که قادر به پردازش موازی و اجرای محاسبات عمومی با مصرف انرژی مناسب هستند. در دنیای امروزه شاهد هستیم که نرمافزارها به صورتی طراحی میشوند که به پردازش موازی و سنگینتری نیاز دارند و لذا بهره برداری از توان پردازش موازی GPU برای انجام محاسبات عمومی اجتناب ناپذیر است. در معماریهای متجانس، CPU و GPU به صورت مجزا طراحی شده و در عمل همکاری بهینه ندارند. هر یک از این دو پردازندهها به فضای حافظه خود نیاز دارد و نرمافزار باید دادهها را از CPU به GPU و برعکس انتقال دهد.
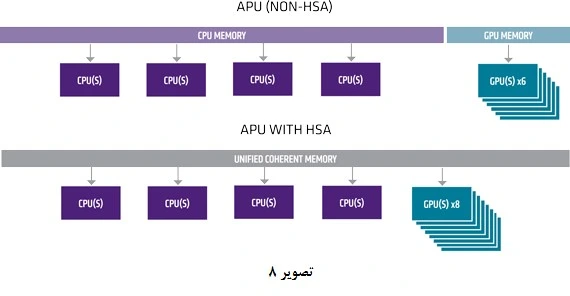
چالش دیگر طراحی و پیادهسازی نرمافزارهایی است که جهت انجام محاسبات عمومی قادر به استفاده از پردازندهی گرافیکی باشند. در یک پردازنده مبتنی بر معماری متجانس، برنامهای که در صف پردازشهای CPU قرار میگیرد با استفاده از فراخوانیها (System Call) با GPU تعامل دارد. هر فراخوانی از طریق درایور سختافزاری صورت پذیرفته و طبیعتا دارای یک صف زمانبندی جداگانه میباشد. بنابراین تأخیر زمانی زیادی در آمادهسازی دستورات پردازشی بوجود میآید و بهرهگیری از GPU جهت محاسبات موازی و عمومی هنگامی مقرون به صرفه خواهد بود که پردازش درخواست شده بسیار سنگین باشد. در واقع در اجرای نرمافزارهای متداول از توان بالقوه GPU چندان استفاده نمیشود و CPU مسئول اجرای بیشتر پردازشها است.
با توجه به چالشهای مطرح شده برای اینکه تمام قدرت پردازشی یک پردازنده مورد استفاده قرار گیرد، طراحان معماری پردازنده در شرکت AMD طرز فکر خود را تغییر داده و در معماری HSA عناصر متفاوت پردازشی را در قالب یک پردازنده مرکزی قرار داده و با ارائه OpenCL مسیر نرمافزارنویسی سادهای را در اختیار توسعهدهندگان نرمافزار قرار دادند تا برای طراحی و پیادهسازی نرمافزارهایی که از پردازندهها به شکل بهینه استفاده میکنند، به تغییرات اساسی کدها نیازی نباشد.
با استفاده از معماری HSA تمام مزایا و توانمندیهای عناصر پردازشی قابل برنامهریزی پردازنده که در کنار یکدیگر به صورت یکپارچه فعالیت میکنند در دسترس قرار میگیرد. بنابراین نرمافزارها قادر به ایجاد ساختارهای دادهای در یک بخش از فضای حافظه نهان یکپارچه هستند و اشتراک داده بین اجزاء پردازنده به سادگی ارسال یک اشارهگر میباشد. در معماری HSA چند فعالیت پردازشی در کنار هم و به شکل منسجم روی یک ناحیه از حافظه قابل اجرا میباشد و از عملیات حافظهای مورد نیاز برای همگامسازی حافظه استفاده میشود. در معماری HSA دادهها بین هستههای پردازشی و گرافیکی بدون کپی شدن و با بهرهبرداری از حافظه نهان به اشتراک گذاشته میشود.
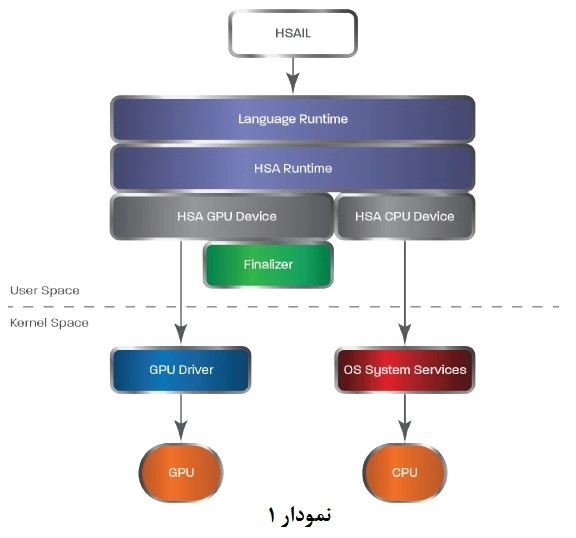
برای استفاده گسترده از معماری HSA بنیاد HSAF ایجاد شده است تا به عنوان یک استاندارد باز در صنعت پردازش، شرکتهای مختلف را گرد هم جمع و هماهنگ نماید. در حال حاضر چندین شرکت مانند AMD، ARM ،Imagination echnology ،Quallcomm ،Texas Instruments و Samsung به این بنیاد پیوستهاند. هدف بنیاد HSAF کمک به طراحان سیستم است تا به شکلی موثر از عناصر پردازشی APU نظیر CPU و GPU استفاده نموده تا ناکارآمدی اشتراک داده و سایر مشکلات موجود برطرف شود. از طرفی یک لایه واسط سطح پایین به نام HSA Intermediate Language (HSAIL) جهت استفاده نرمافزار از سختافزار معرفی شده است. تفکیک نوع پردازش (گرافیکی/محاسباتی) بدین صورت است که درایور GPU در سطح کِرنِل سیستمعامل وظیفه انتقال درخواست ابزار گرافیکی مبتنی بر معماری HSA را به GPU برعهده دارد. سرویسهای سیستمعامل وظیفه انتقال درخواست ابزار غیرگرافیکی مبتنی بر معماری HSA را به CPU را انجام میدهند (نمودار 1).
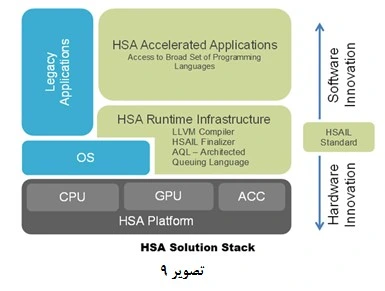
مهمترین عامل موفقیت معماری HSA سادهسازی فرآیند آمادهسازی و اجرای نرمافزار بر روی سختافزارهای متفاوت مبتنی بر معماری HSA است. در گذشته برای هماهنگی و اجرای یک نرمافزار روی یک سختافزار جدید باید نرمافزار تغییر میکرد و این روش چندان مناسب و راحت نبود. برای عمومی شدن یک نرمافزار میبایست مشارکت تمامی توسعهدهندگان و سازندگان سختافزار ساده و امکانپذیر باشد. بستر موجود در HSA شامل سختافزار، واسط و زبان میانی مشترک و اجزای زمان اجرا میباشد (تصویر 9). HSA هماهنگی حافظه ومدیریت صفهای کاری و پنهانسازی پیچیدگیها از دید توسعهدهنده نرمافزار را انجام میدهد. با استفاده از بستر HSA، زبان برنامهنویسی و کتابخانههای آن، ابزاری ساده برای طراحان برنامههای کاربردی فراهم میشود تا از کدهای خود برای سختافزارهای مختلف به شکل بهینه استفاده نمایند. شرکت AMD به عنوان یکی از شرکتهای پیشرو، بستر و ابزارهای برنامهنویسی بهینهشده HSA را برای زبانهای OpenCL ،C++ AMP ،C# ،Java و Python ارائه نموده است.
OpenCL
OpenCL زبانی برای استفاده از پردازندههای نامتجانس است. OpenCL مخفف Open Computing Language است و بستری جهت طراحی و پیادهسازی برنامههایی است که برپایه سکوهای ناهمگن و نامتجانس برای اجرا از CPUها و GPUها استفاده مینمایند. عنوان شد که در حالت متعارف پردازنده یا CPU وظائف پردازشی را انجام میدهد و پردازشهای گرافیکی بر عهده پردازنده گرافیکی (GPU) است. در سال 2007 میلادی برای اولین بار شرکت اَپِل (Apple) این ایده را مطرح نمود که با توجه به پیشرفتها و قابلیتهای پردازندههای گرافیکی این امکان وجود داشته باشد که GPU مشابه CPU وظائف پردازشی محاسباتی انجام دهد. البته شرکت اپل با توجه به معماری Fusion شرکت AMD در آن زمان مبنی بر پردازندههای نامتجانس و APUها این ایده را ارائه نمود. اولین پیاده سازی OpenCL در سال 2008 میلادی توسط Khronos Group انجام پذیرفت. در سال 2009 میلادی دو شرکت AMD و nVIDIA پردازندههای گرافیکی خود را که از OpenCL پشتیبانی مینمود ارائه کردند. در همان سال شرکت اپل سیستم عامل Mac OS X Snow Leopard را ارائه نمود که پیاده سازی کاملی از OpenCL در آن انجام شده بود.
C++ AMP
C++ Accelerated Massive Parallelism (C++ AMP) مدل برنامهنویسی برای زبان (++C) است که توسط شرکت مایکروسافت جهت بهرهبرداری از قابلیتهای محاسباتی GPU بر پایه DirectX 11 توسعه یافته است. به عنوان مثالی ساده برنامه جمع دو آرایه تکبعدی پنج عضوی در (++C) و C++ AMP را در کُدهای ذیل مشاهده نمائید.
// C++
#include <iostream>
void StandardMethod() {
int aCPP[] = {1, 2, 3, 4, 5};
int bCPP[] = {6, 7, 8, 9, 10};
int sumCPP[5];
for (int idx = 0; idx < 5; idx++){
sumCPP[idx] = aCPP[idx] + bCPP[idx];
}
for (int idx = 0; idx < 5; idx++){
std::cout << sumCPP[idx] << "\n";
}
}
// C++ AMP
#include <amp.h>
#include <iostream>
using namespace concurrency;
const int size = 5;
void CppAmpMethod() {
int aCPP[] = {1, 2, 3, 4, 5};
int bCPP[] = {6, 7, 8, 9, 10};
int sumCPP[size];
// Create C++ AMP objects.
array_view<const int, 1> a(size, aCPP);
array_view<const int, 1> b(size, bCPP);
array_view<int, 1> sum(size, sumCPP);
sum.discard_data();
parallel_for_each(
// Define the compute domain, which is the set of threads that are created.
sum.extent,
// Define the code to run on each thread on the accelerator.
[=](index<1> idx) restrict(amp)
{
sum[idx] = a[idx] + b[idx];
}
);
// Print the results. The expected output is "7, 9, 11, 13, 15".
for (int i = 0; i < size; i++) {
std::cout << sum[i] << "\n";
}
}
در کُدهای فوق تابع عناصر آرایههای aCPP ،bCPP به صورت موازی با یکدیگر نظیر به نظیر جمع شده و نتیجه در عناصر آرایه sum ذخیره و سپس چاپ میشود. نکته قابل توجه در کد C++ AMP، انجام محاسبات جمع دو آرایه توسط GPU میباشد.
معماری گرافیکی GCN
Graphics Core Next (GCN) نام معماری جدید پردازندههای گرافیکی AMD است. در نسلهای قبلی از معماری پردازندههای گرافیکی Cayman استفاده میشد که ساختار VLIW4 داشت. شرکت AMD با موفقیت معماری جدید GCN را استفاده کرده تا KAVERI از نظر پردازندهی گرافیکی، قدرت بالایی داشته باشد. در ضمن معماری کارتهای گرافیکی Radeon 200 نیز مبتی بر معماری GCN است و در این حالت با یکسان شدن معماری گرافیکی در کارتهای گرافیکی و پردازنده گرافیکی، توسعهدهندگان نرمافزار دیگر نیازی به بهینهسازی کُدها برای دو معماری متفاوت ندارند.
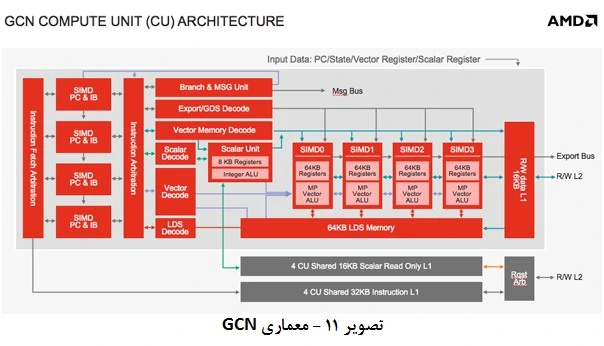
در معماری GCN 1.1 واحدهای پردازشی میتوانند به شکل غیر همزمان، به زمانبندی و اجرای کارهای پردازشی بپردازند. به عنوان مثال در پردازنده A10-7850K با 8 واحد پردازشی مواجه هستیم که به شکل 8 پردازندهی گرافیکی کوچکتر فعالیت میکنند. مهمترین ویژگی معماری GCN که شرکت AMD بر روی آن تاکید فراوان دارد Mantle است. Mantle یک واسط برنامهنویسی سطح پایین است که به سازندگان موتور سهبعدی بازیها، اجازهی بهینه کردن آن را میدهد؛ چرا که فراخوانی ترسیمها کاهش مییابد. Mantle در اعمال Single Thread پردازنده اصلی موثرتر است زیرا شرکت AMD همیشه در عملکرد تکهستهای از شرکت Intel عقبتر بوده و AMD امیدوار است که پردازنده KAVERI با استفاده از Mentle حرف تازهای برای گفتن داشته باشد. شرکت AMD اعلام نموده که پردازنده KAVERI با استفاده از Mentle در بازی Battlefield 4 که از موتور سهبعدی Frostbite 3 استفاده مینماید، 45% افزایش سرعت در اجراء داشته است. شرکت AMD در آزمایش کارت گرافیکی R240 با 2 گیگابایت حافظه GDDR3 و پردازندههای گرافیکی هشتگانه پردازنده KAVERI استفاده نموده است (مشابه حالت Crossfire دو کارت گرافیکی).
منابع
- فرشاد وحیدپور، “پردازنده Pentium 4“، ماهنامه رايانه، شماره 103، (1380)
- فرشاد وحیدپور، “معماري 64 بيتي و پردازنده شش هستهاي AMD Phenom II X6”، ماهنامه رايانه، شماره 201، (شهريور 1389)
- George Kyriazis, ” Heterogeneous System Architecture: A Technical Review” ,AMD ,(2012)
http://developer.amd.com/wordpress/media/2012/10/hsa10.pdf - Ian Cutress & Rahul Garg ,”AMD Kaveri Review : A8-6600 and A10-7850K Tested” ,(Juanary 14 , 2014) ,http://www.anandtech.com/show/7677/amd-kaveri-review-a8-7600-a10-7850k
- AMD White Paper,” AMD GRAPHICS CORES NEXT (GCN) ARCHITECTURE” , (June ,2012)
http://www.amd.com/us/Documents/GCN_Architecture_whitepaper.pdf - Hilbert Hagedoorn ,” AMD Kaveri launches January 14th as A10-7850K” , (December ,2013)
http://www.guru3d.com/news_story/amd_kaveri_launches_january_14th_as_a10_7850k.html - Chris Angelini ,” AMD A10-7850K And A8-7600: Kaveri Gives Us A Taste Of HSA” , (January 16, 2014)
http://www.tomshardware.com/reviews/a10-7850k-a8-7600-kaveri,3725.html





